バイオイメージ・インフォマティクス
バイオイメージインフォマティクスとは?
静止画や動画として観察される様々な生命現象について,画像情報処理技術を駆使して,現象の客観的定量化,ならびに定量化結果からの知識発見に挑む,新しい学際的研究分野.詳しくは,下の解説記事をご覧下さい.
- [ 内田,生体の科学,2017]
- [ 内田,医用画像情報学会雑誌,2017]
- [ 内田,信学誌,2015]
- [ 内田,MIT誌,2015]
- [ 内田,映像メディア誌,2013]
多物体同時追跡(GFP輝点)
蛍光により可視化されたタンパク質分子を動画像中で追う問題.同じ見えを持つ大量の輝点を,低フレームレートの動画の中で追うという,相当困難な課題.ネットワークフローや動的計画法などの大局的最適化法を利用.北大薬学の鈴木研との共同研究.
- [ 藤崎,信学技報,2013]
- [ Chiba,MBC,2014]
多物体同時追跡(メダカ)
時に停止し,時に高速移動もするメダカ.1匹の場合だけでなく,近接や接触を伴う複数匹の場合も含め,追跡アルゴリズムを開発中.基礎生物学研究所渡辺研との共同研究.
多物体挙動可視化のためのカイモグラフィ
線上を移動する物体の動きを2次元的に可視化したものがカイモグラフィ.このカイモグラフィの生成とその解析を容易にするソフトを実装し,公開.北大薬学鈴木研との共同研究.
スライスからの三次元再構成
超高精細にスキャンされたマウス胚のスライス画像系列.この系列を二段階最適位置合わせすることで,3D情報を復元.時空間計算を如何に効率化するかもポイント.基礎生物学研究所藤森研との共同研究.
深層学習を用いた特定生体組織の切り出し
スライス画像からの特定臓器の切り出し.深層学習(CNN)でテクスチャの非常に微妙な差異を定量化し,グラフカットで最適分割.基礎生物学研究所藤森研との共同研究.
[原田,信学技報,2018]
共焦点画像列からの樹状突起ならびにspine検出
焦点深度を変えながら撮影された画像系列から,神経樹状突起をまず検出.その際にはボケによる深さ推定を行う.その後樹状突起周辺に存在するspineを検出し,その形状を定量化する.弱教師付き学習の一種であるMultiple instance learningの問題設定として解ける点が面白い.北大薬学鈴木研との共同研究.
- [八尋,信学技報,2019]
- [藤吉,信学技報,2018]
- [野口,信学技報,2015]
細胞形状定量化(細胞膜)
細胞膜の凹凸(Bleb)構造のダイナミクスを定量化.動的計画法に基づく最適輪郭抽出,輪郭移動速度の定量化,さらにピーク検出に基づく凹凸数の自動定量化.九大生物池ノ内研との共同研究.
細胞形状定量化(分裂細胞)
細胞の分裂方向予測のための細胞領域抽出およびその形状定量化.京大ウイルス研豊島研ならびに遺伝研木村研との共同研究.
細胞内微小構造抽出
画像処理に因る微小管などの細胞骨格の抽出およびその配列方向定量化,オプティカルフローとその配列方向との相関解析.遺伝研木村研との共同研究.
柿の「へたすき」の画像診断
柿の「へた」の部分に隙間ができてしまう「へたすき」.その有無を「へた」が見えない状態(≒木に実った状態)で推定できるか? 岡山大の赤木研との共同研究.
柿の「種なし」の画像診断
柿をモチーフとした「見えないものを見る」シリーズ第二弾.種の有無も果実表面からある程度推定できることを証明.岡山大赤木研との共同研究.
医療データ解析
医用画像解析
医学も画像を多用する分野の一つです.最近では,深層学習等の機械学習を活用した診断支援や医用画像解析が,世界的に活発に研究されています.我々は現在,特に消化器内視鏡学会とのコラボレーションを進めています.
大規模内視鏡画像データベース作成支援
深層学習等で内視鏡画像診断支援を行うためには,その前段階として大量の正解ラベル付きデータセットを作る必要がある.その手間を少しでも低減するために,制約付きクラスタリングに基づくgroup-based labelingや,撮影順序の利用,さらにそのための特徴抽出などを研究.
- [Harada, Med. Img. Anal., 2021]
- [Bise, MICCAI, 2019]
- [Harada, EMBC, 2019]
- [安部, PRMU, 2019]
炎症度推定
疾患(潰瘍性大腸炎)部位の炎症の程度を推定するには,炎症以外の情報(例えば臓器自体の情報)は不要です.disentanglement技術を使えば,画像中の炎症度情報だけを取り出せます
- [Harada, MICCAI,2021]
ランク学習による炎症度推定
ある内視鏡画像だけを見せられて「これは炎症度3だ」というのは医師でも難しい.一方,2枚の画像を見らせられて「どちらがひどいか」を判定(対比較)するのは,比較的容易.この考えに基づけば,対比較だけで学習パターン中の全内視鏡画像を炎症度順に並べることができます.
- [門田, PRMU, 2021]
画像情報学を介した様々な学術分野とのコラボレーション
画像情報学はどのような学術分野ともコラボ可能
あらゆる学術分野において「画像」は使われています.顕微鏡,医用画像,監視映像,外観検査など,対象観察のために使われたり,歴史的資料を保管するために使われたり,デザインのように人間の創作物であったり,その関りは様々です.これら画像を,「単に見て終わり」ではなく,そこに潜む情報を解析し,さらに役立てようとするならば,画像情報学の技術の利活用が必至となります.このように画像情報学は様々な学術分野とコラボレーションが可能です.実際当研究室においても,上記のバイオイメージインフォマティクスだけでなく,様々な分野の研究者とコラボレーションさせていただいています.
- [to appear]
人文学との協働による古文書(花押)解析
花押といは戦国武将のサイン.二つの花押がどの程度似ているかは古文書解析にも重要.人間が無意識に判断している類似度(メトリック)を計算機に模倣させるメトリックラーニングを利用して挑戦.埼玉工大の大山航先生,そして東京大学とのコラボ.
- [鬼塚, じんもんこん, 2018](学生奨励賞 受賞)
- [Onizuka, ICDAR, 2019]
深層学習による台風発生領域の検出
気象シミュレータによるデータ拡張で膨大な事例を生成し,それを用いて台風の卵を学習.JAMSTEC松岡先生との共同研究.憧れていた気象系初コラボ!
スポーツ動作解析・スポーツインフォマティクス
スポーツのうまい人と違う人で,どこの動きがどのように違うのか?センシング技術と照合(マッチング)技術を駆使して,両者を比較.スポーツ科学の専門家とのコラボも実施中.
- [角,映像情報メディア学会技術報告, 2018]
- [角,MIRU, 2017]
サバ稚魚の異常行動解析
サバ稚魚泳動の長時間ビデオから,共食いを異常行動として自動検出.九大農学部松山先生,長野先生との共同研究.
To appear
匂い蛍光画像認識
特定の匂いに対して蛍光を発する化学物質を複数利用して,多様な匂いの空間的分布を定量化.どの物質がどこに存在するかについては,シンプルにNearest-neighborすなわち事例ベースで解決中.九大システム情報 林研との共同研究.
- [ 吉岡,信学技報,2014]
- [ 古澤,信学技報,2012]
- [ Matsuo,JRM,2012]
環境内文字情報の利活用
環境内の文字情報~その検出・認識・分析
あなたは今,この画面の文字を読んでますね?そのためには,文字を瞬時に見つけ,さらに認識しています.この人間には非常に容易なタスクも,計算機にとっては難問中の難問.当研究室も様々なアプローチで挑んでいます.さらに,環境内の文字は,様々な情報を提供してくれています.我々も日々それらに助けられながら生活しています.そこで,認識した文字情報の活用法についても,多角的に研究しています.
情景内文字消しゴム (Scene Text Eraser)
深層学習による画像処理により,情景内の文字だけを選択的に消すという,一見すると魔法のような技術.深層学習がドンピシャでハマった例.柳井先生(電通大)との共同研究.
情景内文字拡大鏡
情景内文字消しゴムとは逆に,情景内の文字部分だけ拡大表示できないか? これを深層学習でやろうとすると,実は文字消しゴムよりずっと難しい.
- [Nakamura, ICDAR, 2019]
- [中村, 信学技報, 2018]
文字を含む情景画像のハイブリッド超解像
超解像とは,画像の解像度を向上させる画像処理技術で,最近では深層学習を活用した方法が増えています.さて問題.「文字という,エッジを主体とした特殊な画像」と「一般の情景画像」,同じ超解像手法を適用すれば十分なのでしょうか?
- [中尾, 信学技報, 2019](PRMU月間ベストプレゼンテーション賞)
- [Nakao, ICDAR, 2019]
Reading-Life Log
「目で見た文字をすべて認識してログ化し,検索可能にする」.我々人間は日々文字を読みながら情報を収集し,生活している.従ってそのログ化は我々の知識のログ化とも言える.大阪府立大・東北大・慶応大との共同研究.
- [ 黄瀬,信学誌,2015]
- [ Kunze,Computer,2013]
- [ Kimura,ICDAR,2013]
- [ 木村,信学技報,2013]
Word2vecによる情景内単語の意味解析
「街中の単語群はどのような意味を持つものが多いのか?」「新聞内の一般的な単語群と異なる意味傾向があるのか?」という問いに,ニューラルネットによる意味定量化法word2vecで挑む.街中の単語群は,一般な単語群に比べ意味的に限定されていることを証明.
Show, Read, and Tell
画像から自動的にその説明文を作るのがImage captioningと呼ばれる技術.情景内の文字情報を使って,説明文のさらなる高精度化に挑む.牛久先生(東大,当時)との共同研究.
[川口, 信学技報, 2018]
情景内テキスト情報を用いた場所・行動認識の高度化
もし「お会計」というテキストがあれば,その画像は店内.「カレーライス」があればその画像はレストラン.このようにテキスト情報はそこがどこで何をすべきところかを示唆する.一般的な画像認識と情景内文字認識を結びつける研究.次の研究とは双対.
情景とその中に見える単語の関係解析
「お会計」という単語があればおそらくそこは店内である.このような情景とそこに写った単語の関係性を,Places365データセット中の画像180万枚を使って調査した.
- [塩山, CVIM, 2020]
物体とその上に印字された単語の共起性解析
"Shampoo"と書いてくれてるおかげで,そのボトルがシャンプーであることがわかる.このように物体表面に印字された単語は,その物体がなんであるかを明示するためのラベルとして機能する.ではどんな単語がどんな物体上にあるか? 170万枚の画像を使って,その共起性を実際に調査した.
ネットワーク最適化に基づく文書レイアウト解析
人間はテキスト行を簡単に目で追える.縦組み・横組み混在時ですら追える.計算機にこの機能を持たせるために,ネットワーク最適化とディープラーニングを組み合わせた手法で挑む.
環境コンテキスト利用による情景内文字検出
「どこに文字があるか?」~人間にとっては無意識にできる問題も,計算機にとっては非常に難問. 実際,「文字らしさ」だけで情景内の文字を検出しようとすると,誤検出が多発する.そこで周囲の状況を認識する.例えば周囲が空や森なら,そこには文字は無い.最近の試みでは畳み込みニューラルネットワークも積極的に利用.
多重仮説に基づく情景画像内文字検出
我々の身の回りの文字は極めて多様.ゆえに単一の方法で検出できるわけがない.そこで逆に複数の異なる方法を使って検出を試み,それらの結果を適切に統合する.言わば「三人寄れば文殊の知恵」的なアプローチ.Palaiahnakte Shivakumara博士との共同研究.
- [ Huang,IEICE,2013]
- [ Huang,ICPR,2012]
- [ 大場,信学技報,2011]
グラフカット最適化による情景内文字列検出
文字を認識するためには,文字の検出が必要で,文字の検出のためには,それが文字であることを認識する必要がある.「卵が先か,鶏が先か」タイプの問題.これを一気に解決するために,最適化の枠組みで認識と検出を同時実行する.
- [ 武部,信学論,2014]
位相構造学習による情景画像内文字検出
文字の様々な形状変化を表現するために,その構造をグラフで表現.その際,機械学習(gBoost)を用いて,文字らしい構造,らしくない構造の代表例を自動選出.文字検出に応用した.
局所特徴を用いた文字検出
「文字のかけら(断片)に文字らしさはあるのか?」という問いに,肯定的に答えた研究.文字の断片,および非文字の断片をそれぞれ局所特徴として表現,それらが機械学習で求めた識別器で区別できることを証明.
情景画像中文字の選択的隠蔽
時にはプライバシー侵害にもなる写真中の文字情報を,どうやったら消せるのか?すなわちどうすれば文字の可読性を破壊できるのか?「文字は文字によってこそ破壊される」ことを実証.
- [ Inai,ICPR,2014]
- [ 稲井,信学技報,2013]
情景画像中文字の視覚的顕著性(visual saliency)
「情景内の文字は,見つけて読んでもらってこそ意味がある.従って目立っているだろう」という疑問を,大規模データセットおよび視覚的顕著性を用いて解消.予想通り,情景内の文字は目立つように配置されていた.Faisal Shafait教授との共同研究.
情景内文字の色頻度解析
世界では,どのような色の文字が使われているのか?背景との組み合わせはどうか?デザイナが暗黙に使う文字とその背景の色彩関係を,大量の情景内文字データを使って,定量的に解析.
- [ Gao,ICDAR,2015]
- [ 江口,信学技報,2015]
大規模情景内テキストデータセット
情景内に存在する文字・テキストの意味を様々な角度から調べるために,3000枚の画像中にある文字領域を,画素レベルでラベリング.世界最大規模の高精度データセットを構築した.
ユニバーサルパターンプロジェクト
大阪府立大(黄瀬教授,岩村准教授),東北大(大町教授)と,10年以上の長きに渡り続いている大学間プロジェクト.文字を検出・認識しにくいというのなら,文字自体を検出・認識容易にしてしまおうという,逆転の発想がベース.文字でまだまだ面白いこともできる!
- [ Kise,IEICE,2015]
- [ Uchida,ICDAR,2007](論文賞)
ビジュアルデザインの情報学的解析 (Visual-Design Analytics)
ビジュアルデザインの秘密を情報学的に解明する
書籍表紙やフォントなどに代表される画像デザインは,なぜそのようにデザインされているのか? なぜ「寿司屋の看板は毛筆体」「甘いお菓子は丸ゴシック」なのか? このデザイナの経験知を,膨大なデータを解析することにより,工学的に解明する試みです.
書籍タイトルフォントの形状とジャンルの相関解析
世の中のフォントやその色は,その文脈にフィットするように選ばれている.タイポグラファーによるこの選択に潜む秘密を書籍表紙画像を題材に解き明かす.
デザインを認識する~書籍表紙画像からのジャンル認識
深層学習を用いて書籍表紙画像から(タイトルを認識せずに)その書籍のジャンルを当てるという野心的な試み.これが結構認識できるのが面白いところ.
深層学習はどのようにデザインを認識しているのか?
どの辺を手掛かりに,深層学習は書籍ジャンルを認識しているのか? 認識結果に最も影響を与えている画素を推測することで,この問いに答える.
- [Jolly, ICPR, 2018](ICPR2018 Best Student Paper Award)
GANによるフォントの自動デザイン
深層学習による画像生成のフレームワークGAN (Generative Adversarial Networks)を用いてフォントを自動生成.識別器による評価も加えることで,より自然なフォントに近づけるといった工夫も.
- [Abe, ACPR, 2017]
- [阿部,信学技報,2017]
- [阿部,信学技報,2018]
- [Hayashi, Knowledge-Based Systems, 2019](Preprint PDF)
特定印象を持ったフォントの自動デザイン
エレガントなフォント,セリフ付きフォント,太いフォント,読みやすいフォント.そういう特定の印象・性質を指定した上でフォント画像を生成.
二つのフォントの違いを使って,新しいフォントを生成
「形の足し算と引き算」でフォントを新しく作るというユニークな研究.そのためにNeural Style Transferを拡張.この考えは,より一般化することもでき,「形の代数演算」的な話にもつながると期待.
フォントの印象はどこから来るのか?
「このフォント,カワイイ」「真面目そう」「エレガント」「読みやすい」.こういう印象はフォントの形のどこからやってくるのか? 「形とその印象の関係」という古くからの課題に,フォントと大規模データ,そして機械学習により挑む.
フォントネットワーク
多様なフォントの世界を,フォント間の類似性を用いてネットワーク表現.ネットワーク上のツアー(tour)により,フォントの変化をモーフィング的に観察もできる.さらに,ネットワークの中心を見ることで「文字Aとは何か?」という人工知能の根本問題にもアプローチ.
文字の自動デザイン(フォントネットワーク利用)
フォントネットワークの「穴」,それはまだデザインされたことのないフォントの指定席.ネットワーク解析により「穴」を見つけ,さらにアウトライン情報を用いたフォントのモーフィングにより,未開のフォントを自動生成する.
多フォント同時アライメント
「文字Aとは何か?」シリーズの研究.Congealingと呼ばれる摂動法を用いて,6000種のフォントを非線形同時位置合わせ.すなわちお互いになるべく似たように微調整を重ねる.その収束結果は,非常に一般的なサンセリフ体であった.
- [ Uchida,ICDAR,2015]
- [ 江頭,信学技報,2015]
- [ 江頭,信学技報,2013]
グラフマッチングによるフォント構造解析
「文字は線状,その多様性はその線状構造の変形で表せる」...すなわち文字はグラフ表現できる.ならば文字はグラフマッチングで認識できるのか?古典的ながら未解決な疑問に対し,高効率グラフマッチング手法で挑む.Andreas Fischer博士との共同研究.
検出容易なフォントの選出
情景画像から文字を見つけるのは難しい.ならば見つけやすい文字というものはどういうものか?という逆転の発想の研究.その原理は「非文字から最も遠いフォントが,最も非文字とは区別しやすい」.この原理で選ばれた文字を見てみると...
- [ 小泉,信学技報,2013]
- [ Uchida,ICDAR,2009]
- [ 服部,信学技報,2009]
フォントスタイルからの年代推定
デザインには流行がある.フォントもその一つである.実際,映画のポスターの文字を見たとき,「古臭い」とか「最近の映画だろう」とか,なんとなくわかる.では,計算機にそういう年代推定ができるのだろうか? できるとすれば,どこをどう見ているのだろうか?
フォント同一性判定
機械は「絶対フォント感」を持つのか? 二つの文字が同じフォントかどうかを判定する問題に,計算機は非常に高い精度で答える!
リリックビデオ解析
YouTube等で見られる歌詞が音楽に乗って縦横無尽に動き回るlyric video.どんな曲にはどんな動きが合うのか? 産総研後藤先生・加藤先生との共同研究.
書籍表紙にフィットするフォントスタイル選び
書籍表紙は,専門のデザイナによって入念にデザインされている.タイトルを印字するフォントもその構成要素の一つ.では表紙デザインが画像として与えられたら,機械学習はどのようなフォントでタイトルを印字するだろうか?
書籍表紙画像生成
書籍表紙は,専門のデザイナによって入念にデザインされている.既存の書籍表紙画像をつかった機械学習で,なんとか素人でも表紙デザインをしてみたい! この辺にピザの画像を置いて,この辺を塗りつぶして,この辺にタイトルをドーンと…
ロゴの自動デザイン
ディープニューラルネットワークの応用である "Neural style transfer"を利用して,様々な模様のロゴや飾り文字を自動デザイン.
- [Gantugs,PLoS ONE,2020]
- [Gantugs,DAS,2018]
- [Gantugs,ICDAR-WML,2017]
- DeNA様との関連プロジェクト ""Fontgraphy" (製作者鼎談)
ロゴデザインの業種別解析
企業のロゴはどのようにして企業イメージを与えているのか? Top-rank learningというランキング学習の一種を用いて,各業種に特有のデザインの傾向をあぶりだす.
ロゴとフォロワーの関係
ロゴは企業の「顔」である.ではどのような企業がどのようなロゴデザインなのか? 企業のtwitter follower数とロゴデザインの関係を探ったところ,弱いながらも面白い傾向が見えてきた!
Iconify: 写真のアイコン化
アイコンやピクトグラムなどのグラフィックスは,実際の写真をモチーフにしたものが多い.では写真から自動でアイコンはできるのか? そもそも写真とアイコンの違いは何なのか?
深層学習をはじめとする様々な機械学習の応用
ディープニューラルネットワークと深層学習のインパクト
ディープニューラルネットワークとその学習法である深層学習.さらには学習に必要な大規模データとGPUをはじめとする高性能計算資源.これらが画像情報学・パターン認識研究を劇的に進展させています.当研究室でも,以下の課題だけでなく,他の多くの課題(バイオイメージインフォマティクス研究や文字科学研究など)に応用しつつ,その挙動を解析してています.
「Max pooling = 変形抽出」という考え方
CNN内部で行われているmax pooling処理.これには情報集約や変形吸収の効果があります.後者について逆に見れば,対象がどのような変形をしているかを抽出しているのです.従来利用されていなかったこの変形情報を「もったいない」ので有効活用したい,というのがモチベーション.さらに検討を進めた結果,筆記者識別にも非常に有効であることも示されている.
特殊なユニットを持ったニューラルネットワーク:非線形変動吸収機能を持ったニューロン
深層学習(DNN)の仕組みに非線形マッチング(DTW)の考え方を世界で初めて導入.時系列パターン等に起こる非線形変動を吸収可能にすることでDNNのさらなるパワーアップ化に成功.
特殊なユニットを持ったニューラルネットワーク:要素間相関計算機能を持ったニューロン
ニューラルネットワークを構成するユニット(ニューロン)は,ニューロンが持つ重みと入力(ベクトル)との内積を行う.これに対して,当研究室の早志助教が入力ベクトル間の要素どおしの積を可能したニューロンを構築.普通のニューラルネットワークではできない処理・性能の実現を目指し,基礎・応用の両面で検討中.
- [Hayashi, ACCV, 2018]
- [Lee, ICDAR, 2019] (文書画像の図分離への応用)
CNNの判断理由解析(explainable AI)
畳み込みニューラルネットワークが判断根拠としている部分は画像上のどこにあるのか? 世界中が取り組んでいるこのexplainable AIの課題に,当研究室も取り組む.
- [黒木, 信学技報, 2019]
- [Iwana, ICCV-WS, 2019]
CNNの内部状況解析
深層学習(CNN)の内部でパターンの分布はどのように変化していっているのか? ネットワーク分布解析技術でそれを可視化.その結果,「手書きと飾り文字がCNN内部のどこで同一視されるのか?」も判明.
- [ Ide, ICDAR, 2017]
- [ 井手, 信学技報, 2016](PRMU月間ベストプレゼンテーション賞)(2016年度PRMU研究奨励賞)
CNNのpoolingのメタ学習
CNNの中で情報集約や変形補正のために使われるPooling.無批判に使われてますが,本当は対象毎に適したpoolingを学習して使ったほうが良いのでは?→ Yes.
正則化Pooling
CNNの変形補正機能を担うMax Pooling.局所独立に最大値を選択するのだが,多くの変形が滑らかに生じることを考えれば,局所独立は変では? というわけで,局所独立性を緩和してみた.
CNNの部分パターン検出能力に関する基礎検討
深層学習(CNN)を使えば,画像からどのような部分パターンを検出できるのか.例えば,「国」「園」のような漢字画像から,安定して「口」(くにがまえ)があると検出できるなら,CNNは,部分パターンの内部変化に非常に頑健であると言える.
- [ Iwana, ICDAR, 2017]
- [周, 情報研資, 2017]
CNNの挙動からパターンの急所を探る
認識にあたり,画像のどの部分がキモなのか? どの部分が欠けたら認識できなくなるのか? 数字パターンを使って徹底解析.
マルチモーダルな単語の意味ベクトル化
機械学習の進展により,言葉の意味を数値(ベクトル)で表現することも可能になってきました.このとき,たとえば同じ"Sound"という単語でも,黄色い活字で印刷されたときと,ぐちゃぐちゃな手書きで書かれたときでは,少し違う意味になっていそうです.また"hot"と"cold"をベクトル化するとき,それらが赤と青で印字されていることを活用すれば,その意味の違いをより強調できそうです.このような意味の数値化に言語外情報を使う研究をやっています.
- [Ikoma, DAS, 2020]
- [生駒, 信学技報, 2019]
CNNのアンサンブル学習
「三人寄れば文殊の知恵」のように,複数の機械学習を組み合わせることでより強い機械学習結果にするのが,アンサンブル学習です.では,深層学習(CNN)のように元々強い機械学習を組み合わせると,もっと強くなるのでしょうか? また,もっともっと強くするにはどのように組み合わせればよいのでしょうか? そしてもし組み合わせるだけで強くなるのなら,でたらめに作られたCNN(ランダムニューラルネットワーク)でも組み合わせれば高精度になるのでしょうか?
- [杉原, 信学技報, 2019]
CNN特徴による最適リジェクト
パターン認識の極めて重要な考え方である「リジェクト」は,「これは認識できません」と自動判断させる処理である.認識と同程度に困難とされていたリジェクトを,理論保証を持った機械学習の枠組みで実施するための研究.
- [Ji, ACPR, 2019]
CNNの学習率の最適化
CNNのようなニューラルネットワークを学習するとき,その学習率が常に問題になります.よく「最初は学習率を上げ,徐々に下げる」という経験的戦略が採られるのですが,本当にそれでよいのでしょうか? 我々は「オンライン予測」という機械学習を使い,その学習率の最適化を図っています.
- To appear.
ランキング学習(learning to rank)による個人認証
ランキング学習とは,より「あるクラスらしい」サンプルxが上位に来るような関数r(x)を求めるタスク.これを筆記識別のような個人同定に用いれば,「Aさんらしい」サンプルxを検出できる関数f(x)が実現できる.
- [Yan, ICDAR, 2019]
トップランク学習と深層学習の合体
トップランク学習とは,簡単に言えば「この辺のデータは絶対に正常(正例)」と言い切ってくれる学習法.なので,医用データのスクリーニングにはもってこい(←「この辺のデータは正常だから医師が見るまでもないですよ」と言ってくれるから.)
単位初期化による深層ニューラルネットワークの収束性解析と挙動解析
通常乱数で初期化される深層ニューラルネットワーク.これに対して各層を単位行列で初期化すると,どんなに多層でも入力がそのまま出力されるようなネットワークを構成できる.さて,この単位初期化で見えてくるものは何か? 富士通研究所との共同研究.
時系列パターンの認識・解析
非類似度空間埋め込みによる大規模時系列認識
深層学習とも密接な関係がある(非)類似度空間埋め込み(Dissimilarity space embedding).パターンそのものの特徴を記述するのではなく,他のパターンとの類似度を特徴とする.本研究は,その枠組み大規模化かつ時系列パターン認識に拡張したもの.
GANによる時系列パターン生成
Generative Adversarial Networks(GAN)は様々な画像を生成する手法として有名ですが,実は時系列データの生成にも拡張可能です.我々は生体信号の生成に活用中です.
- [Harada, IEEE Access, 2019]
- [Harada, EMBC, 2018](2018 Excellent Student Award of the IEEE Fukuoka Section)
局所距離特徴を用いた時系列パターン認識
ある時系列パターンを認識する際,基準パターンと局所的にどれぐらい相同しているかを特徴とする方法.シンプルながら非常に高い認識精度を達成.
ニューラルネットワークによる非線形マッチングを用いた時系列パターン認識
時系列データの比較照合法として長年利用されてきたdynamic time warping (DTW).これをニューラルネットワークによる距離学習の枠組みで学習可能にすることで,自由度が向上.
Cross Variational Autoencodersによる手書き画像の時系列パターンへの変換
手書き画像は,ペン先の運動軌跡であり,従って時系列パターンとしての側面も持っている.この「画像と時系列」という二重性に注目し,手書き画像から,それを筆記した際の時系列を復元する難題に挑戦.
時系列パターンの早期認識
終わりを待たずに認識結果を出せるのが「早期認識」.機械学習法であるAdaBoostを改良することで,早期認識のための識別器系列を構成.基本アイディアは「時刻tでまだ認識できないものを時刻t+1で認識するための学習」.
- [ 白石,信学技報,2012]
- [ 天本,信学技報,2008]
- [ Uchida,ICPR,2008]
- [ Mori,ICPR,2006]
- [ 森,ロボット誌,2006]
画像と系列データの相互変換によるマルチモーダルパターン認識
画像だけども輪郭のような系列データとして見たほうが認識しやすかったり,逆に系列データだけども画像化したほうが認識しやすかったり.そうならば,画像と系列のモダリティの壁を越えた認識系を作ればよいのでは?
時系列パターンのためのデータ拡張法
深層学習を使って時系列データを認識したいのだがデータが足りない.そこでデータ拡張(data augumentation, DA)を使うのだが,適切なDAを使わないと認識率は却って悪化する.時系列データの種類とそれに適したDA法を網羅的に調査.
非マルコフ時系列パターンマッチング
(隣ではなく)遠く離れたところの関係性を制約可能な,ちょっと変わった時系列パターンマッチング.従来不可能だった詳細なマッチング制御を可能にした.MIRU2011優秀論文賞.Volkmar Frinken博士と共同研究.
- [ Kakisako,ICDAR,2015]
- [ 柿迫,信学技報,2015]
- [ Frinken,ICFHR,2014]
- [ Uchida,ICPR,2012]
- [福冨,MIRU,2011](優秀論文賞)
- [ 福冨,信学技報,2011]
K-最近傍時系列パターンマッチング
2つの時系列パターン間に,互いに異なる複数の対応付けを同時かつ最適に求める方法.一種の整数計画問題になるが,問題の性質により線形計画問題として解いても整数解が得られる点が,計算量的に助かる.
- [ 深澤,信学技報,2015]
特徴非同期時系列パターンマッチング
時系列パターンは,特徴ベクトルの1次元系列として表現される.そのマッチングの際,特徴ベクトルを成分ごとに分けて扱うとどうなるか?実はパターンを最適変形させながらマッチングするという新機能を実現できる.
- [ 佐々木,信学技報,2011]
- [ Uchida,ICDAR,2011]
- [ Uchida,ICFHR,2008]
- [ 二矢川,信学技報,2007]
解析的DPによる時系列パターンマッチング
組み合わせ探索としての扱いが多い時系列パターンマッチング.その常識を覆した.マッチングコストを二次関数近似することで,探索無しで最適解が求まり,計算量も劇的に減少.画像の認識・理解シンポジウムにおいて,長尾賞(最優秀論文賞)を受賞.
- [ Uchida,NORDIA,2012]
- [ 内田,信学論,2007]
- [ 内田,MIRU,2006](論文賞)
大局的特徴とその最適選択
時系列パターンについて,離れた2時刻間の関係を表現するのが大局的特徴.ではどの2時刻間の特徴を使えば,認識性能が向上するか? さらに時系列非線形伸縮マッチング(DTW)との相性をよくするには?機械学習の枠組みで挑む.NTTとの共同研究.
- [ Mori,PRL,2014]
- [ Ogata,ICFHR,2014]
- [ 森,信学論,2013]
大規模人流データからの異常検出
街中に配置された複数のセンサーからリアルタイム人流データについて異常を検出.夜中に忍び寄る人物や,日中の極端な人だかりなどを異常としてリアルタイム検出可能.Markus Goldstein博士を含む大学内共同研究.
- [ Goldstein,PLOS ONE, 2016]
- [Goldstein,ICPRAM,2016]
- [亀津,MIRU,2016]
論理的DPによるモチーフ検出
動的計画法による最適パターンマッチングについて,その目的関数に論理関数を導入.どの局所的マッチングペアも必ず一定誤差以下で対応付けられている,という制約を実現.モチーフ(頻出パターン)の検出に応用.
- [ Uchida,ACCV,2007]
- [ 森,信学論,2007]
大局的最適な多数決に基づく時系列パターン認識
各時刻ごとにクラスAかBかを判別.ある時刻までの認識結果は,判別結果の多数決で決める.その際,時刻毎に完全に独立して判別されると不安定なので,隣接時刻は「なるべく」同じクラスにする.一種の最適化問題となり,グラフカットアルゴリズムで解ける.
断片化に基づくオンライン文字認識
上記のテーマをさらに進め,(画像ではなく)タブレットから入力される運動(運筆)軌跡としての文字を断片化.結果,文字は単なる「短い曲線分の集合」になってしまう.それでもかなり認識できることを実験的に証明.文字は強し.
- [ Matsuo,IGS,2013]
- [ 松尾,信学技報,2013]
オンラインマルチストローク文字の認識
漢字などの多画文字では,多様な筆順変動が発生する.筆順変動は,筆記運動としての文字パターンを全く違うものにしてしまい,誤認識の深刻な原因に.本研究では,どのような筆順変動が起きているかを積極的に推定し,誤認識を避ける方法を確立させる.
- [ Cai,FCS,2014]
- [ 片山,信学論,2008](論文賞)
- [ 蔡,信学論,2005]
画像の認識・解析
ニューラルネットワークによる画像処理モジュール群の生成と,そのパイプライン化
古典的な画像処理では,パイプラインといって,所望の画像処理結果を得るために,複数の画像処理を直列接続していた(例えば,ノイズ除去フィルタ→膨張収縮処理→二値化).ここでもし各画像処理をニューラルネットワークで実現できれば,それらを直列接続することで,さらに高度な画像処理を実現できるのではないかと考えた.
複数のトラッカ(物体追跡アルゴリズム)のオンライン統合
物体追跡は依然困難な問題であり,特定のトラッカが万能であるとは考えにくい.そこで複数のトラッカを適切に統合して利用することを考える.この統合には,最新の機械学習理論であるオンライン予測を利用し(末廣助教が専門家),「こちらのトラッカを使っておけばよかったのに」という後悔度(リグレット)を理論的に抑えつつ,トラッキング精度を担保する方法を開発.
- [Song, WACV, 2020]
多段階最適化に基づく多物体同時追跡
頻繁に接触・交差し,時に並走するような対象を前提として,トラックレットへの分解,トラッキングによる接触部検出,トラックレット接続,を大局的最適化の枠組みで実装.
- [ 山口,信学技報,2015]
深層学習を用いた一般物体追跡
深層学習とDPを組み合わせた,見えの変化やオクルージョンに非常に強いトラッキング手法.
- [ Lee, PSIVT, 2017]
- [Lee,九支大, 2016](Excellent Presentation Award)
- [ Lee,arXiv,2016]
非マルコフ的制約下での多物体同時追跡
「ちょっと前にあそこで見たアレは,いまここにいる」.そういう知識を世界で初めて活かせるトラッキング手法.
- [ 徳永,信学技報,2016]
解析的DP を用いた動画像中の物体追跡
物体追跡はいまもホットな研究課題で応用先も広い.様々な方法の中,動画像全体の情報を使って追跡経路を全体最適化するアプローチがあり,精度が高い反面,計算量的な問題があった.精度を落とさず計算量を落としたのが本手法.
- [ 藤村,信学論,2009]
- [ Uchida,ACCV,2010]
- [ 川野,信学技報,2010]
画像から画像への言語変換
計算機上で言語は普通unicodeのような符号列で表され,翻訳等の変換も符号変換として行われる.本研究は「とある言語(ハングル)の画像(=ビットマップ)」を,明示的に文字認識することなしに,「他の言語(英語)の画像(=ビートマップ)」に変換できることを示した,変態的研究.実は,画像を使ったことで,未学習の文字であっても変換できるという,隠れた効果もある.
科学文書画像中の数式検出
タイトルの通り,文書画像中の数式を,ニューラルネット(U-net)で検出する.簡単そうに見えるが,実はf(x)のように文中に埋め込まれた数式もあり,これまでは困難とされていた.大量の正解付きデータと深層ニューラルネットワークの併用で高精度に実現.埼玉工大教授の大山航先生と九大名誉教授の鈴木昌和先生の共同研究.
畳み込みニューラルネットワーク(CNN)によるユニバーサルOCR
手書き・活字,そして人間にすら読めないようなデザインフォントを含むデータセットを,深層学習は読めるのか?実用的な意味を持ちながらも,実は人間と機械にとっての可読性の差異を問う基礎的研究.
Deep LSTMによる文字列認識
リカレントニューラルネットワークの代表格であるLSTMを多層化.この巨大なネットワークで,手書き文字列を左から右にデコード(認識)していく.どのような多層化がよいのか?何層の多層化が必要か?層間の結合形式は? Volkmar Frinken博士との共同研究.
Canonical Time Warping (CTW)による輪郭マッチング
時系列パターンの非線形マッチング(DTW)に回転不変性を導入したものがCTW.本研究では同手法を輪郭マッチングに拡張,形状認識問題への利用可能性を探る.
- [ 松村,信学技報,2015](PRMU研究奨励賞)
断片化に基づく手書き文字画像認識
文字はバラバラにしても読めるのか?世界に先駆け,この疑問に肯定的な答えを出した研究.すなわち,文字は大局的な構造がなくてもある程度読める.ポイントは多数決原理.一般的な画像認識研究における局所特徴の有効性とも密接に関連.
- [ Wang,FCS,2013]
- [ Wang,ICDAR,2013]
- [ Wang,ICPR,2012]
- [ Uchida,ICPR,2010]
- [ Uchida,ICFHR,2010]
- [ 内田,信学技報,2010]
解析的2次元DPマッチング
当研究室で提案した解析的DPマッチングを2次元すなわち画像マッチングに拡張.高速かつ大局的に最適な非線形画像マッチングを実現.ちなみに,組み合わせ最適化の枠組みで同じ問題を解こうとしても,NP-Complete問題となり現実的には解けない.
固有変形解析
パターンの変形はランダムではない.ならばその変形の傾向にはどのようなものがあるのか?この問いに答えたのが,非線形な画像マッチングと主成分分析で求めた固有変形.パターンの任意の変形は,この固有変形の線形和で近似可能.
- [ Uchida,PR,2003]
- [ Uchida,ICDAR,2003]
- [ 内田,信学論, 2004]
- [ 三苫,情報論, 2004]
- [ Mitoma,ICDAR,2005]
学習による映像中の一般音源同定
画面内のどの部分が今の音を出したのか,我々は無意識に理解する(実際に音が出ているのが画面横のスピーカーだとしても).この機能が膨大な視聴覚経験に依るという仮説の下,その経験を機械学習させることで,映像中の音源同定を行なう.
- [ 池田,信学技報,2010]
機械学習による最適カメラ選択
サーベイランスでは複数のカメラが同一視野を観察している状況がある.その際,視野内の人物の特定動作を認識するには,すべてのカメラを使う必要はない.では,どのカメラが有効か?本研究では機械学習により自動的にカメラを取捨選択する.
- [ 首藤,信学技報,2008]
大規模事例に基づく動画像予測
人間なら,1枚の静止画から,その過去や未来の状況を想像できる.この機能の工学的実現を目指す.「人間は膨大な過去の視覚体験に依って想像する」という仮説に基づき,大量の動画像を利用して「工学的想像」を実現.
- [ 岩切,信学技報,2013]
- [上村,MIRU,2014]
- [岩切,MIRU,2012]
- [ Iwakiri,ICFHR,2012]
大局的観測と局所的観測の統合による複数人物の無矛盾な位置同定
各人に装着したカメラと全体を俯瞰するカメラからの情報を組み合わせ,「この映像を映している人はどこにいるのか」を推定する.一種の「一人称ビジョン」問題.最適一対一マッチング問題として定式化できる点が,解決の鍵.
局所特徴を用いた写真内文書の傾き推定
文書画像の傾き補正は,OCRの前処理として重要である.文字行を検出できれば簡単であるが,スライドやポスターなどなど短い文字行ではそれができない.そこで画像の局所毎に事例ベースで回転を推定し,その結果を画像全体で統合する方法を採る.
局所特徴を用いた位置同定
人間は,GPSが無くても,以前来た場所であれば,情景画像からそこがどこかわかる.すなわち位置を認識できる.本研究では,局所特徴を用いて画像を断片化した上で位置を認識する.断片化により,情景内に起こり得る様々な変化に頑健になる.
- [ 村山, 信学技報, 2013]
- [ 小野, 信学技報, 2010]
大規模パターンの分布解析
大規模パターン集合(Big Data)を扱う意義

よく聞く「Big Data」なる単語.バズワードと揶揄されますが,パターン認識にとって膨大なデータを扱うことは,極めて本質的で重要な点です.従来は少量のデータしかありませんでしたので,パターンは正規分布やガウス混合分布のような単純なモデルで分布していると仮定されていました.これに対し,膨大なパターン集合があれば,分布の真の姿を見ることができます.さらにその真の姿を解析することで,認識精度の向上や,アルゴリズムの効率化も図れます.
ネットワークを用いた大規模パターン集合の分布解析
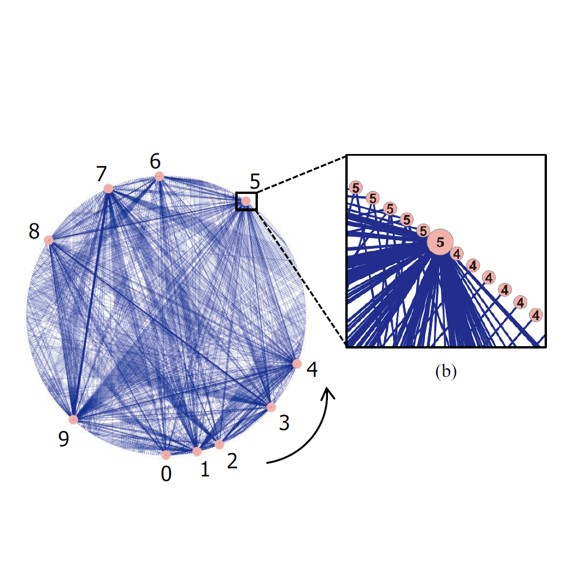
「高次元パターンの分布の真の姿を見たい」「クラス間の境界の状況を把握したい」というモチベーションで開始した研究.高次元空間の低次元化は誤差が生じる.そこでネットワーク解析の方法を利用.解析結果はSVM学習のパターン予備選択にも利用可能.
- [
井手,信学技報,2015]
- [
Goto,ICDAR,2015]
- [
Goto,ICDAR,2013]
- [
後藤,信学論,2013]
- [
石田,信学技報,2013]
大規模パターン集合の分布解析

大量のパターンはどのような分布をしているのか?...この問題に最近傍パターンとの関係を利用して挑む.上記のネットワーク解析の前段階として位置づけられる試みであるが,パターンの欠損部補完など,思いがけない成果も生んだ.
最適化によるクラス境界と真のクラス境界の差異
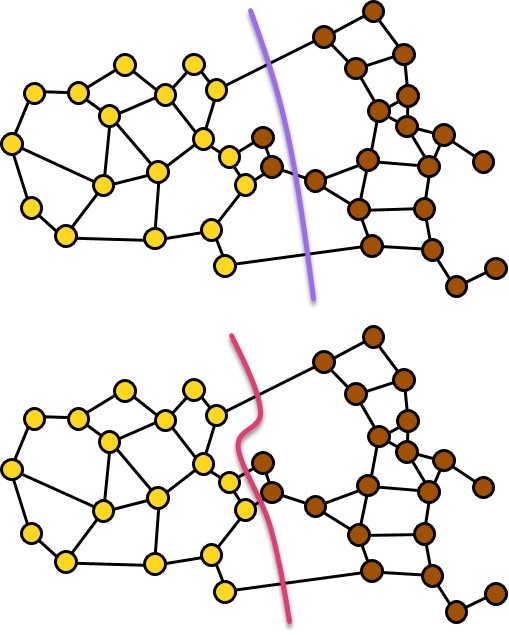
多クラスのパターン集合をある最適化の枠組みで分離したとします.この分離境界は真のクラス境界とどのように違うのでしょうか? 同じならば,パターンそのものの生成原理が,上記の最適化の枠組みに従っていることになります.違うならば,なぜ,どのように違うのでしょうか?
- [
井手,信学技報,2015]
大規模パターン認識のための高速最近傍探索
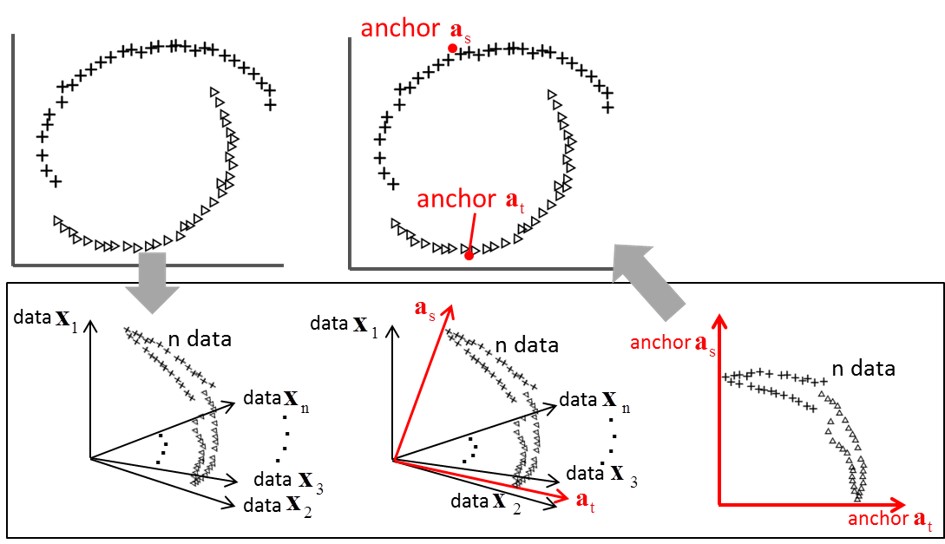
「クラス未知の入力パターンに対し,クラス既知のパターン集合の中から最も似たものを探索し,そのクラスを認識結果とする.」これが最近傍識別である.この単純な手法もパターン集合が膨大になると,探索に要する計算時間が現実的でなくなる.この問題に対し,AGHなる方法を拡張して挑む.
大規模パターン集合(Big Data)を扱う意義
よく聞く「Big Data」なる単語.バズワードと揶揄されますが,パターン認識にとって膨大なデータを扱うことは,極めて本質的で重要な点です.従来は少量のデータしかありませんでしたので,パターンは正規分布やガウス混合分布のような単純なモデルで分布していると仮定されていました.これに対し,膨大なパターン集合があれば,分布の真の姿を見ることができます.さらにその真の姿を解析することで,認識精度の向上や,アルゴリズムの効率化も図れます.
ネットワークを用いた大規模パターン集合の分布解析
「高次元パターンの分布の真の姿を見たい」「クラス間の境界の状況を把握したい」というモチベーションで開始した研究.高次元空間の低次元化は誤差が生じる.そこでネットワーク解析の方法を利用.解析結果はSVM学習のパターン予備選択にも利用可能.
- [ 井手,信学技報,2015]
- [ Goto,ICDAR,2015]
- [ Goto,ICDAR,2013]
- [ 後藤,信学論,2013]
- [ 石田,信学技報,2013]
大規模パターン集合の分布解析
大量のパターンはどのような分布をしているのか?...この問題に最近傍パターンとの関係を利用して挑む.上記のネットワーク解析の前段階として位置づけられる試みであるが,パターンの欠損部補完など,思いがけない成果も生んだ.
最適化によるクラス境界と真のクラス境界の差異
多クラスのパターン集合をある最適化の枠組みで分離したとします.この分離境界は真のクラス境界とどのように違うのでしょうか? 同じならば,パターンそのものの生成原理が,上記の最適化の枠組みに従っていることになります.違うならば,なぜ,どのように違うのでしょうか?
- [ 井手,信学技報,2015]
大規模パターン認識のための高速最近傍探索
「クラス未知の入力パターンに対し,クラス既知のパターン集合の中から最も似たものを探索し,そのクラスを認識結果とする.」これが最近傍識別である.この単純な手法もパターン集合が膨大になると,探索に要する計算時間が現実的でなくなる.この問題に対し,AGHなる方法を拡張して挑む.
ヒューマンインタフェース
情報埋め込みペンの開発

ペン先に小型インクジェットノズルを搭載した,世界で初めての情報埋め込みペン.筆記の際にモールス信号状に情報を埋め込む.5cmの手書きに32ビットを誤りなく埋め込めることを実証.Marcus
Liwicki博士との共同研究.
- [
Liwicki,PRL,2014]
- [
内田,信学技報,2011](招待)
- [
Liwicki,DAS,2010]
- [
田中,HI誌,2008]
- [
Uchida,IWFHR,2006]
カメラプロジェクタシステムによるタッチスクリーンの実現

小型カメラを準備してスクリーンを撮影でするだけで,何の変哲もないスクリーンをタッチパネルにしてしまう技術.スクリーンに写ったウインドウを指先でドラッグして移動できることを実証.
- [
吉田,信学技報,2012]
ペン先カメラ画像からの手書きパターン復元

ペン先に装着した超小型カメラから,紙面の繊維構造(紙紋)を読み取ることで,ペン先の動きすなわち筆記内容を推定.ビデオモザイキング技術により実現.光学式マウスの原理に似るが,ペンの傾きによる射影変換,照明変化,動きボケなど,困難性も多い.
- [
Chikano,PRL,2014]
- [
内田,信学論,2010]
- [
Uchida,CBDAR2009]
情報埋め込みペンの開発
ペン先に小型インクジェットノズルを搭載した,世界で初めての情報埋め込みペン.筆記の際にモールス信号状に情報を埋め込む.5cmの手書きに32ビットを誤りなく埋め込めることを実証.Marcus Liwicki博士との共同研究.
- [ Liwicki,PRL,2014]
- [ 内田,信学技報,2011](招待)
- [ Liwicki,DAS,2010]
- [ 田中,HI誌,2008]
- [ Uchida,IWFHR,2006]
カメラプロジェクタシステムによるタッチスクリーンの実現
小型カメラを準備してスクリーンを撮影でするだけで,何の変哲もないスクリーンをタッチパネルにしてしまう技術.スクリーンに写ったウインドウを指先でドラッグして移動できることを実証.
- [ 吉田,信学技報,2012]
ペン先カメラ画像からの手書きパターン復元
ペン先に装着した超小型カメラから,紙面の繊維構造(紙紋)を読み取ることで,ペン先の動きすなわち筆記内容を推定.ビデオモザイキング技術により実現.光学式マウスの原理に似るが,ペンの傾きによる射影変換,照明変化,動きボケなど,困難性も多い.
- [ Chikano,PRL,2014]
- [ 内田,信学論,2010]
- [ Uchida,CBDAR2009]